Where it began
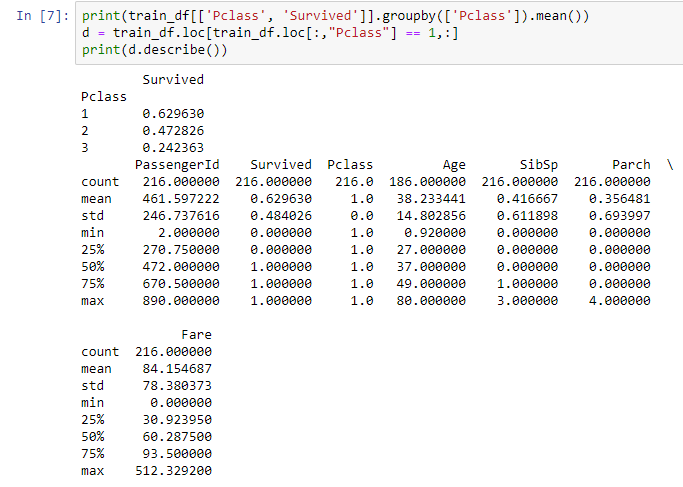
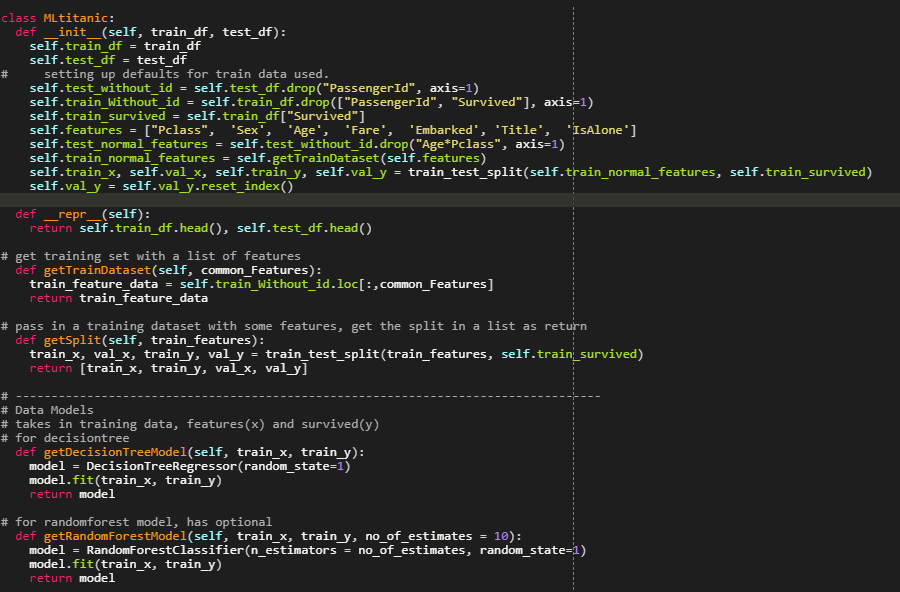
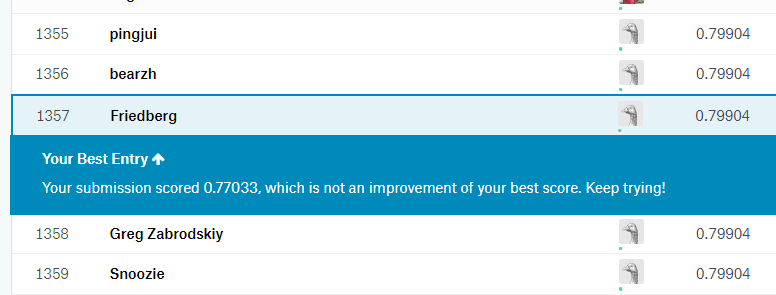
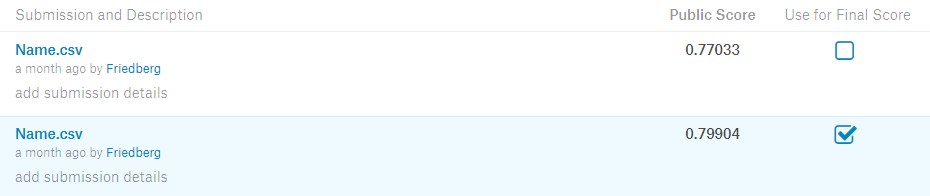
After finishing the basic tutorials for machine learning and data science on kaggle, I wanted to try my hands on an actual dataset and project. This was when I stumbled onto the Titanic dataset where it was not only suited for beginners but also had some tutorials made by other people. This gave me the idea to try the project on my own before I looked at other people's tutorial/solution. This way I was able to experience the project on my own, while still easy access to help if I get stuck. The goal of the dataset was to use some features that the passengers had, and use them to predict the survival rate of the passenger.